今回は赤ワインのデータを見てみる. 五感に基づく分類は試験者に依存すると思うがとりあえず赤ワインの品質分類を行ってみる.
Kaggle にあるのは UCI のコピーだそうなので、UCI の原データを使う. まずはデータの確認.
import pandas as pd
import missingno
red = pd.read_csv('winequality-red.csv', sep=';')
missingno.matrix(red, figsize=(10,8))
red.isnull().sum()
null データは見られない. 各変数の相関を見てみる.
corr = red.corr()
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
fig = sns.heatmap(corr, mask=mask, annot=True, fmt='.2f', annot_kws={"size": 8}, cmap='bwr')
plt.xticks(rotation = 45, fontsize = 10, ha='right')
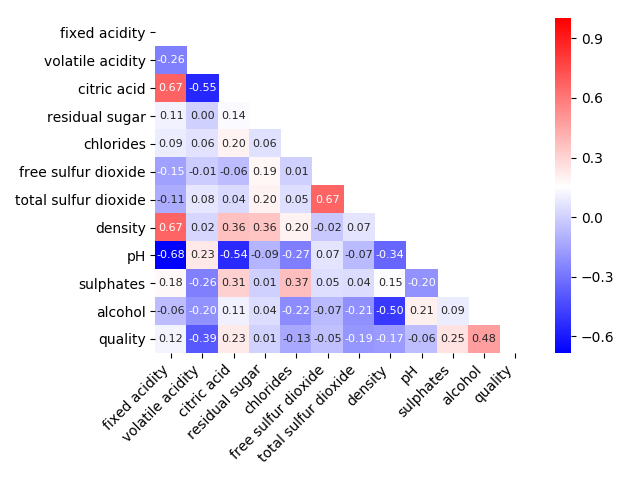 quality と相関がありそうなのは、alcohol, volatile acidity. 次に quality の分布を見てみる.
quality と相関がありそうなのは、alcohol, volatile acidity. 次に quality の分布を見てみる.
import matplotlib.pyplot as plt
plt.style.use('bmh')
bins = np.arange(1, 11) + x0
plt.hist(red.quality + x0, bins=bins)
plt.xlabel('quality')
plt.ylabel('entries/bin')
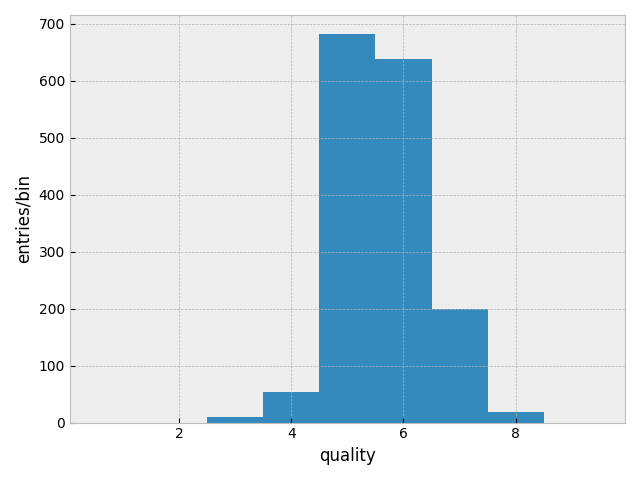 5と6にピーク. 分類の為に、4以下を低品質、7以上を高品質、それ以外を普通とする.
5と6にピーク. 分類の為に、4以下を低品質、7以上を高品質、それ以外を普通とする.
def to_category(x):
if x < 5: return "lo"
elif x > 6: return "hi"
else: return "av"
red['category'] = red.quality.apply(lambda x: to_category(x))
三分類ごとに各変数の分布を見てみる.
import seaborn as sns
df = red.drop('quality', axis=1).melt(['category'], var_name='var', value_name='value')
g = sns.FacetGrid(df, col='var', col_wrap=4, hue="category", height=2.0, palette="Set1", sharex=False, sharey=False)
g = (g.map(sns.distplot, "value", hist=False, rug=True))
plt.legend(loc='upper right', bbox_to_anchor=(1.5, 1.0))
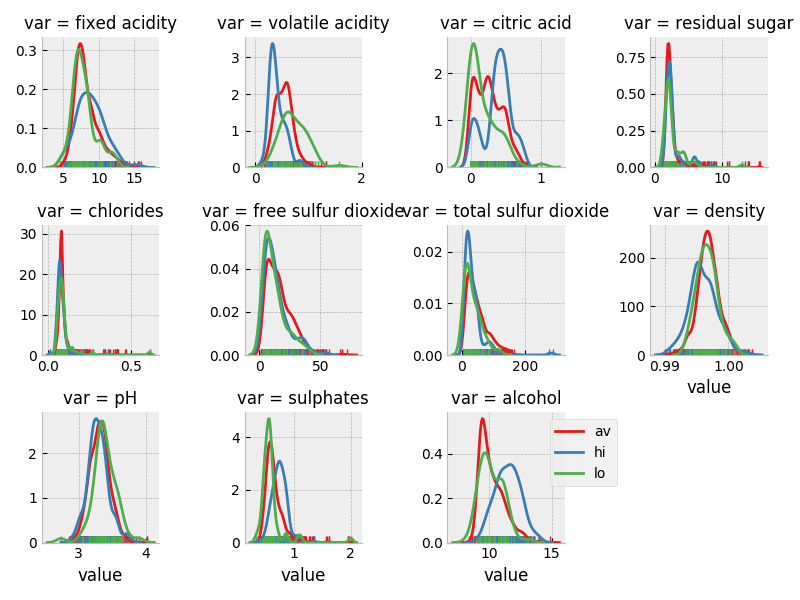 分類に役立ちそうな変数は、alcohol, volatile acidity, citric acid.
データを訓練用とテスト用に、三分類の分布に従って分割し、分類名を数値に変換する.
分類に役立ちそうな変数は、alcohol, volatile acidity, citric acid.
データを訓練用とテスト用に、三分類の分布に従って分割し、分類名を数値に変換する.
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
targets = ['quality', 'category']
X = red.drop(targets, axis=1)
x_train, x_test, y_train, y_test = train_test_split(X.values, red.category.values, stratify=red.category, test_size=0.25, random_state=42)
le = preprocessing.LabelEncoder()
le.fit(red['category'])
y_train = le.transform(y_train)
y_test = le.transform(y_test)
Linear Support Vector Classification
初めに LinearSVC で分類する. その際、GridSearchCV を使用してパラメタースキャンを行う. StratifiedShuffleSplit を使用した交差検証を用いている.
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score, classification_report
import sklearn.svm as svm
steps = [
("scaler", StandardScaler()),
("clf_linearSVC", svm.LinearSVC(dual=False))
]
linSVC_cls = Pipeline(steps=steps)
param_grid = {
'clf_linearSVC__C': [0.0001, 0.001, 0.01, 0.1, 1, 10, 100, 1000]
}
gs_linSVC = GridSearchCV(linSVC_cls, param_grid=param_grid, iid=False, cv=StratifiedShuffleSplit(n_splits=5, test_size=0.1, random_state=13))
gs_linSVC.fit(x_train, y_train)
pred = gs_linSVC.predict(x_test)
print(gs_linSVC.best_estimator_)
print(gs_linSVC.best_params_)
print(gs_linSVC.best_score_)
print(accuracy_score(pred, y_test))
print(classification_report(pred, y_test))
テストデータを用いた正解率は 0.855.
C-Support Vector Classification with Gaussian RBF kernel
同様にして、Gaussian RBF kernel を使用した support vector machine で分類.
steps = [
("scaler", StandardScaler()),
("clf_svm", svm.SVC())
]
svm_clf = Pipeline(steps=steps)
param_grid = {
'clf_svm__gamma': [0.0001, 0.001, 0.01, 0.1, 1, 10, 100, 1000],
'clf_svm__C': [0.0001, 0.001, 0.01, 0.1, 1, 10, 100, 1000],
}
テストデータを用いた正解率は 0.8625.
Random Forest Classification
同様に、Random Forest を用いて分類.
from sklearn.ensemble import RandomForestClassifier
steps = [
("scaler", StandardScaler()),
("clf_rf", RandomForestClassifier())
]
rf_clf = Pipeline(steps=steps)
param_grid = [
{'clf_rf__n_estimators': [100, 200, 500, 1000, 2000, 5000]},
]
テストデータを用いた正解率は 0.875. 各変数の分類への寄与度を見てみる.
plt.bar(X.columns, gs_rf.best_estimator_.named_steps['clf_rf'].feature_importances_)
plt.xticks(rotation = 45, fontsize = 10, ha='right')
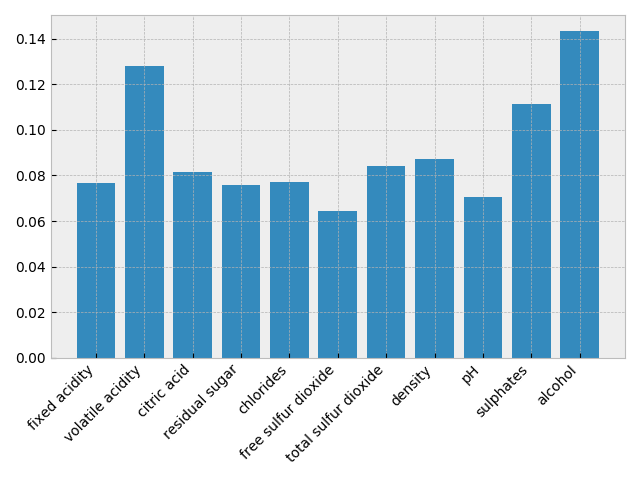 分類への貢献度が高いのは、alcohol, volatile acidity, sulphates.
分類への貢献度が高いのは、alcohol, volatile acidity, sulphates.
Gradient Boosting classification
同様に、XGBoost を用いて分類.
import xgboost
steps = [
("scaler", StandardScaler()),
("clf_xg", xgboost.XGBClassifier())
]
xg_clf = Pipeline(steps=steps)
param_grid = {
'clf_xg__min_child_weight': [1, 5, 10],
'clf_xg__max_depth': [3, 6, 9],
'clf_xg__gamma': [0, 1, 2, 5],
'clf_xg__n_estimators': [1000],
}
テストデータを用いた正解率は 0.8775.
Gaussian Process classification
同様に、Gaussian process を用いて分類.
from sklearn.gaussian_process import GaussianProcessClassifier
steps = [
("scaler", StandardScaler()),
("clf_gp", GaussianProcessClassifier())
]
gp_clf = Pipeline(steps=steps)
param_grid = [
{'clf_gp__max_iter_predict': [100, 200, 500]},
]
テストデータを用いた正解率は 0.8575.
Neural Network classification
同様に、Neural Network を用いて分類.
import keras
def dnn(ninput=11, num_classes=10, hidden_layers=(100,), activation='relu', lr=0.001, dropout=0.2,
loss=keras.losses.categorical_crossentropy):
from keras.models import Sequential
from keras import layers
from keras import optimizers
model = Sequential()
model.add(layers.Dense(hidden_layers[0], input_dim=ninput))
model.add(layers.Activation(activation))
if len(hidden_layers) > 1:
for mlp in hidden_layers[1:]:
model.add(layers.Dense(mlp))
model.add(layers.Activation(activation))
model.add(layers.Dropout(dropout))
model.add(layers.Dense(num_classes))
model.add(layers.Activation('softmax'))
optimizer = optimizers.Adam(lr=lr)
model.compile(optimizer=optimizer, loss=loss, metrics=['accuracy'])
return model
num_classes = 3
Y_train = keras.utils.to_categorical(y_train, num_classes=num_classes)
Y_test = keras.utils.to_categorical(y_test, num_classes=num_classes)
from keras.wrappers.scikit_learn import KerasClassifier
model = KerasClassifier(build_fn=dnn, num_classes=num_classes, batch_size=32, epochs=100, verbose=0)
steps = [
("scaler", StandardScaler()),
("clf_nn", model)
]
nn_clf = Pipeline(steps=steps)
param_grid = [
{'clf_nn__hidden_layers': [(50, 50), (100, 100), (200, 200)],
'clf_nn__activation': ['tanh', 'elu'],
'clf_nn__lr': [0.01, 0.1],
},
]
テストデータを用いた正解率は 0.85.
各アルゴリズム毎の正解率を表にしてみる.
| accuracy | |
|---|---|
| Linear SVC | 0.855 |
| Gaussian RBF SVC | 0.863 |
| Random Forest | 0.875 |
| XGBoost | 0.878 |
| Gaussian process | 0.858 |
| MLP | 0.850 |
簡単なパラメタースキャンの結果、どのアルゴリズムも同程度の正解率をだしている.
最後に XGBoost の confusion matrix を見てみる.
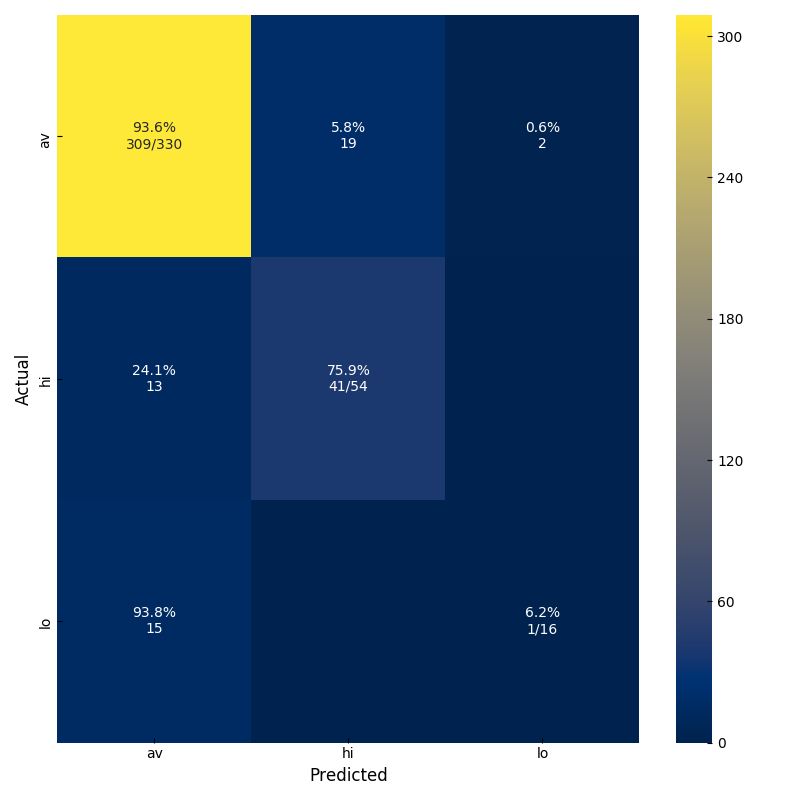 平均的なワインのデータ数が多いために、その正解率が高ければ全体の正解率も高くなる. まずはデータ数を増やす必要があると思うが、高品質なワインの正解率を高めるためには、別の指標を使ってグリッドスキャンを行う等が必要だろう. 以上、赤ワインの分類を行った.
平均的なワインのデータ数が多いために、その正解率が高ければ全体の正解率も高くなる. まずはデータ数を増やす必要があると思うが、高品質なワインの正解率を高めるためには、別の指標を使ってグリッドスキャンを行う等が必要だろう. 以上、赤ワインの分類を行った.