Kaggle の House Prices competition に参加してみた. 鍵となる幾つかの点を纏めておく.
a) null data の取り扱い
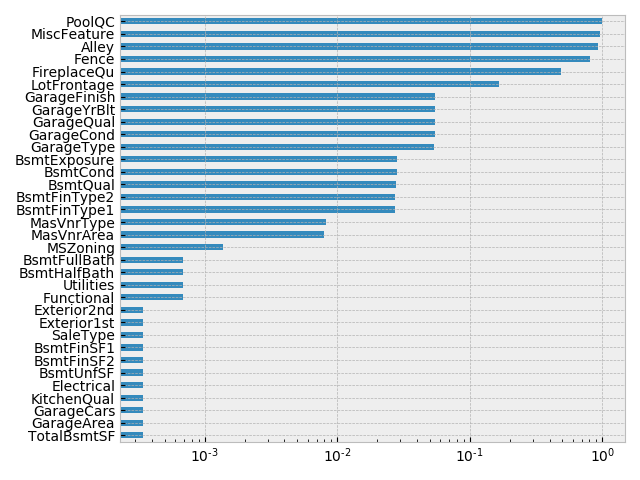
null データを確認する.
has_null = data.columns[(data.isnull().sum()!=0)].values
has_null = data[has_null].isnull().sum()/len(data)
has_null.sort_values(ascending=True, inplace=True)
has_null.plot(kind='barh')
plt.xscale('log')
null データの置換.
# numeric data
features = data.dtypes[data.dtypes!="object"].index
features = features[(data[features].isnull().sum()!=0).values]
for col in features:
data[col].fillna(0, inplace=True)
# categorical data
features = data.dtypes[data.dtypes=="object"].index
features = features[(data[features].isnull().sum()!=0).values]
fillna_cat = {
'Electrical': "SBrkr",
'KitchenQual': data['KitchenQual'].mode()[0],
'Exterior2nd': data['Exterior2nd'].mode()[0],
'SaleType': data['SaleType'].mode()[0],
'Exterior1st': data['Exterior1st'].mode()[0],
'Utilities': "AllPub",
'Functional': "Typ",
'MSZoning': data['MSZoning'].mode()[0],
'MasVnrType': "None",
'BsmtFinType1': "NA",
'BsmtFinType2': "NA",
'BsmtQual': "NA",
'BsmtCond': "NA",
'BsmtExposure': "NA",
'GarageType': "NA",
'GarageFinish': "NA",
'GarageQual': "NA",
'GarageCond': "NA",
'FireplaceQu': "NA",
'Fence': "NA",
'Alley': "NA",
'MiscFeature': "NA",
'PoolQC': "NA",
}
for name in features:
data[name].fillna(fillna_cat[name], inplace=True)
b) outliers の削除
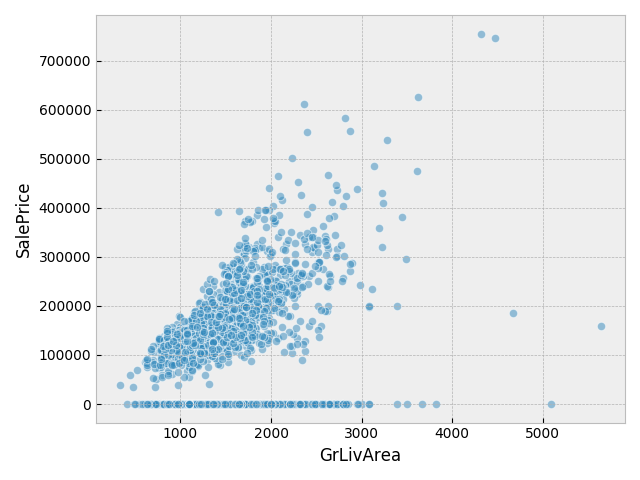
広い居住面積がありながら価格が極端に低い訓練データを削除する.
sns.scatterplot(data['GrLivArea'], data['SalePrice'], alpha=0.5)
data[(data['GrLivArea']>4000)&(data[target]<200000)]
outliers = [523, 1298]
data.iloc[outliers,:]
data.drop(data.index[outliers], inplace=True)
c) feature engineering
基本的に sklearn.linear_model.Ridge の loss が小さくなるようにデータを加工した
- Exterior1st/Exterior2nd の誤字を修正. 二つのカテゴリーを一つに纏める.
- Condition1/Condition2 カテゴリーを一つに纏める.
- YrSold/MoSold を一つに纏めて、数値データからカテゴリーデータに変換.
- MSSubClass を数値データからカテゴリーデータに変換.
- TotalSF を追加.
TotalSF = TotalBsmtSF + 1stFlrSF + 2ndFlrSF - has2ndFlr を追加.
has2ndFlr = 2ndFlrSF > 0 - PoolArea/Electrical/MiscVal/Alley/MiscFeature を削除.
- skew の大きなデータを変換.
scipy.special.boxcox1p(data, scipy.stats.boxcox_normmax(data+1))
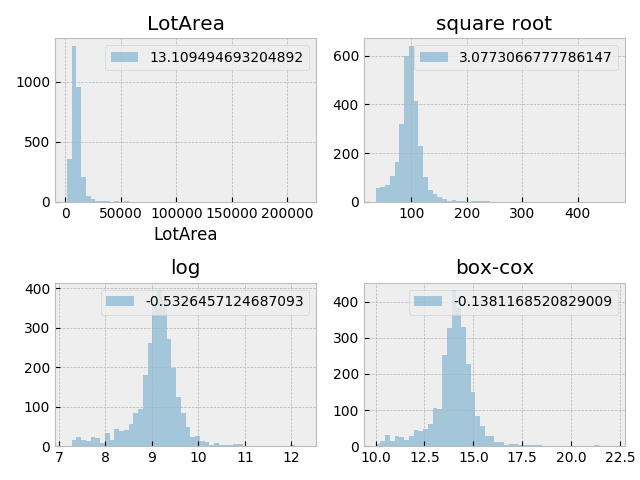 データ変換の例. 左上) 無変換 右上) square root 変換 左下) log 変換 右下) boxcox 変換. 各ラベルは skew 値を示す.
データ変換の例. 左上) 無変換 右上) square root 変換 左下) log 変換 右下) boxcox 変換. 各ラベルは skew 値を示す.
d) visual inspection
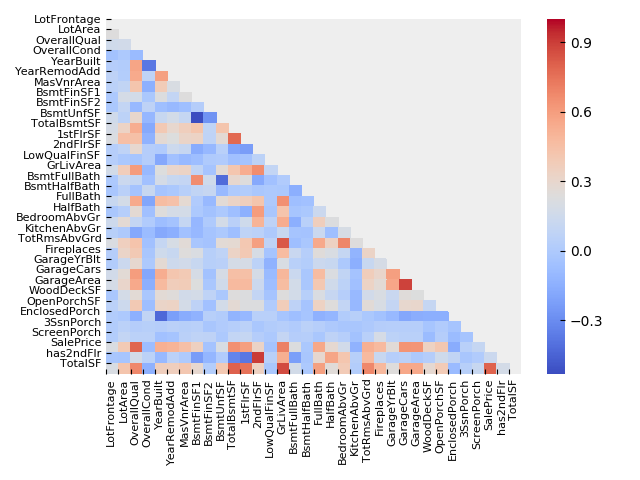
数値データの相関マトリックス
 カテゴリーデータの 1-way ANOVA 分析.
カテゴリーデータの 1-way ANOVA 分析.
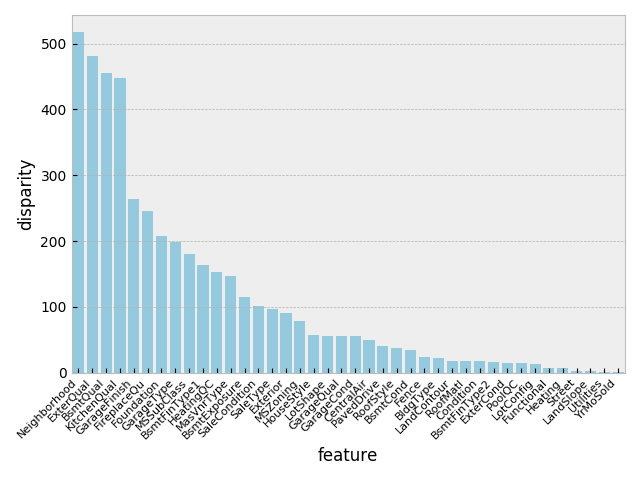
最後にカテゴリーデータを one hot encoding に変換.
pd.get_dummies(data)
e) hyper-parameters tuning of models
sklearn.model_selection.GridSearchCV、sklearn.model_selection.KFold を用いて、各種モデルの hyper-parameter を調整.
- sklearn.linear_model.Ridge
alpha: 13.27 - sklearn.linear_model.Lasso
alpha: 4.83e-4, max_iter: 2000 - sklearn.svm.SVR
C: 8000, epsilon: 0.035, gamma: 1.5e-06 - sklearn.ensemble.GradientBoostingRegressor
learning_rate: 0.1, loss: 'huber', max_depth: 4, max_features: 'sqrt', min_samples_leaf: 5, min_samples_split: 2, n_estimators: 500, random_state: 501, subsample: 0.9 - lightgbm.LGBMRegressor
colsample_bytree: 0.3, learning_rate: 0.05, min_child_samples: 1, min_child_weight: 0.5, n_estimators: 2000, num_leaves: 7, random_state: 501, subsample: 0.1 - xgboost.XGBRegressor
colsample_bytree: 0.55, gamma: 0.03, learning_rate: 0.03, max_depth: 10, min_child_weight: 3, n_estimators: 500, n_jobs: -1, subsample: 0.35
f) model blending
毛色の違う、Ridge、SVR、XGBRegressor を 4:4:2 の割合で結果を作成したところ、スコアは 0.11524 であった. 本稿の投稿時点で、top 9%.