前回、オランダの電力消費量データを見たが、接続毎電力消費量の地域毎のバラツキが大きかったので詳しく見てみる. 最大値は Overijssel 州の 227 kWh、 最小値は Zuid-Holland 州の 148 kWh.
まずは、回線毎電力消費量の分布を見てみる.
data = df[(df.province=='Overijssel') & (df.year==2019)]
data = data[data.active_connections!=0.]
xx = data.annual_consume/data.active_connections
plt.hist(xx, bins=1000)
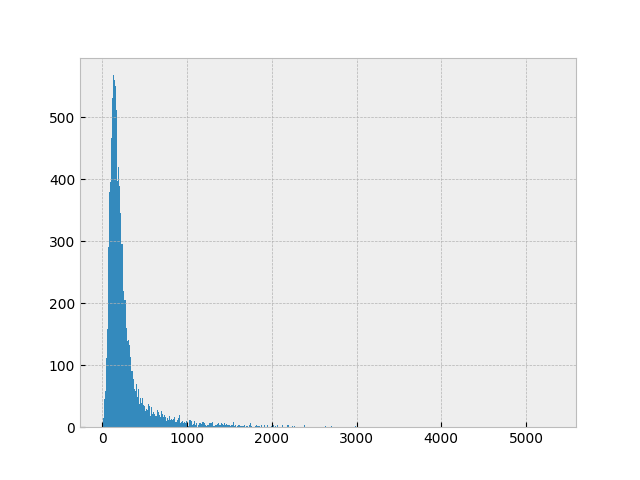 テールを引いている分布なので、Landau 分布の近似である Moyal 分布でフィットしてみる.
テールを引いている分布なので、Landau 分布の近似である Moyal 分布でフィットしてみる.
import scipy
def moyal(x, peak, width, amplitude):
return amplitude*np.exp(-0.5*((x-peak)/width + np.exp(-(x-peak)/width)))
hist, edges = np.histogram(xx, bins=5000)
bin_center = edges[:-1] + np.diff(edges)/2.
popt, pcov = scipy.optimize.curve_fit(moyal, xdata=bin_center, ydata=hist, p0=[1.,1.,1.])
フィットの結果は、ピーク位置が 135.6、幅が 47.7 となり、単純平均の 227 kWh より低い場所にピークがある. 大口の電力ユーザーが大きなテール分布を構成していると推測される. 同様にして、Zuid-Holland 州の分布をフィットすると、ピーク位置が 101.0、幅が 39.1 となる.
二つの州の分布を比較するために、それぞれヒストグラムの最大値で規格化した後に重ねて表示してみる. その際に、フィット結果も表示すると以下のようになる.
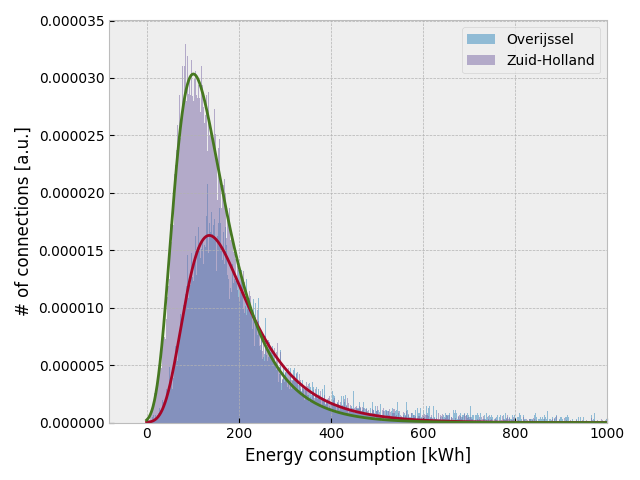
テールを除けば一般家庭の電力使用量になると思われるので、両州とも似たような分布になるかと予想していたが実際は異なっていた. Overijssel 州の方が電化が進んでいて使用量が多いのかも知れないが、手持ちのデータだけでは何とも言えない.
両州のフィット結果の違いを見るために、iminuit を用いて、フィット結果の誤差解析を行ってみる. 損失関数を以下の様に定義する.
data_x = bin_center
data_y = hist
def loss(peak, width, amplitude):
dx = data_y - moyal(data_x, peak, width, amplitude)
return np.sum(dx*dx)
これを、iminuit の migrad で最小化し、hesse/minos と誤差解析を行う.
import iminuit
m = iminuit.Minuit(loss, errordef=1,
peak=100., width=40., amplitude=max(hist),
error_peak=10., error_width=1., error_amplitude=max(hist)*0.1,
limit_peak=(0., None), limit_width=(0., None), limit_amplitude=(0., None))
rc = m.migrad()
rc = m.hesse()
rc = m.minos()
m.draw_mncontour('peak','width', nsigma=3)
plt.scatter(m.values['peak'], m.values['width'], s=100)
plt.title('Overijssel')
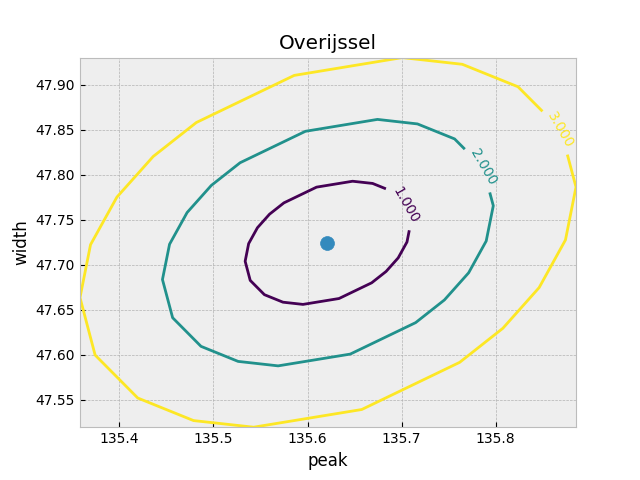
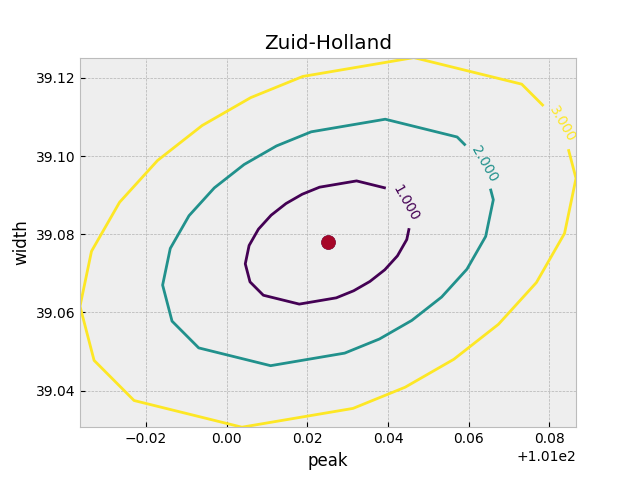 両分布のピーク位置と幅は、それぞれの誤差 (3-$\sigma$) 以上十分に離れているので、有意に異なる分布だと言える.
両分布のピーク位置と幅は、それぞれの誤差 (3-$\sigma$) 以上十分に離れているので、有意に異なる分布だと言える.
以上、接続毎電力消費量の分布を見てみた.