MeCab は日本語形態素解析エンジン. これを用いた日本語処理を試してみる.
Yahoo! Japan の ニュース速報 を解析し、単語の頻度分布を見てみる.
まずは、指定された URL の内容を取得する関数を定義.
from urllib.request import Request, urlopen
from urllib.error import URLError
def get_url(url):
req = Request(url)
try:
response = urlopen(req)
except URLError as e:
if hasattr(e, 'reason'):
print('connection failure')
print('Reason: ', e.reason)
elif hasattr(e, 'code'):
print('The server returned an error')
print('Error code: ', e.code)
return response.read().decode('utf-8')
Yahoo! Japan のニュース速報タイトル一覧と対応するリンク情報を取得する関数を定義.
import lxml.html
def get_news(url):
data = get_url(url)
root = lxml.html.fromstring(data)
doc = root.findall(".//div[@class='newsFeed']")[0]
titles = doc.xpath(".//div[@class='newsFeed_item_title']")
links = doc.xpath('.//a/@href')
news = {}
if len(titles) != len(links): raise NotImplementedError
for idx in range(len(titles)):
title = titles[idx].text_content()
link = links[idx]
news[title] = link
return news
parser と stopwords を定義する.
import neologdn
import MeCab
mt = MeCab.Tagger("-d /usr/local/lib/mecab/dic/ipadic")
import wordcloud
stopwords = set(wordcloud.STOPWORDS)
stopwords.update([chr(i) for i in range(12353, 12436)])
stopwords.update([chr(i) for i in range(12353, 12436)]) # ひらがな
stopwords.update([chr(i) for i in range(12449, 12532+1)]) # カタカナ
stopwords.update([chr(i) for i in range(65296, 65296+10)]) # 全角数字
stopwords.update([chr(i) for i in range(48, 48+10)]) # numbers
stopwords.update([chr(i) for i in range(97, 97+26)]) # alphabet lowercase
stopwords.update([chr(i) for i in range(65, 65+26)]) # alphabet uppercase
stopwords.update(['https', 't', 'co', '%', '.', '@', '/', '_', '?', '(', ')', '#', '!', '|', ')、',
'-', '[', ']', ':', '=', '"', '&', '>', ',', "'", '°', '$', '″', '://', '@_',
')〈', '⇨ ', '_____', '!」', ')。', '?」', '(´', '`)', '%、', '--', '...', '://',
'.…', '??', '①', '②', '③', "ー", "'", "」(", "<「", "<", ")(", ")「", ")」",
")="])
ニュース速報の形態素解析を実効し各名詞の出現頻度を記録する.
Yahoo = "https://news.yahoo.co.jp/flash"
news = get_news(Yahoo)
import collections
nouns = collections.Counter()
for title, link in news.items():
data = get_url(link)
root = lxml.html.fromstring(data)
doc = root.findall(".//p[@class='ynDetailText yjDirectSLinkTarget']")
if len(doc) != 1: continue
text = str(doc[0].text_content())
mt.parse('')
normed = neologdn.normalize(text)
rc = mt.parse(normed)
for line in rc.split('\n'):
try:
word, desc = line.split('\t')
if word in stopwords: continue
except:
pass
features = desc.split(',')
word = features[-3] if features[-3] != '*' else word
part = features[0]
subpart = features[1]
if part == '名詞' and subpart not in set(['数', '接尾', '代名詞', '非自立', '副詞可能']):
nouns[word] += 1
名詞の出現頻度上位20個をヒストグラム表示.
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.family'] = 'IPAPGothic'
labels, values = zip(*(nouns.most_common()[:20]))
indexes = np.arange(len(labels))
width = 1
plt.bar(indexes, values, width)
plt.xticks(indexes, labels, rotation=90)
plt.ylabel('頻度')
plt.tight_layout()
plt.show()
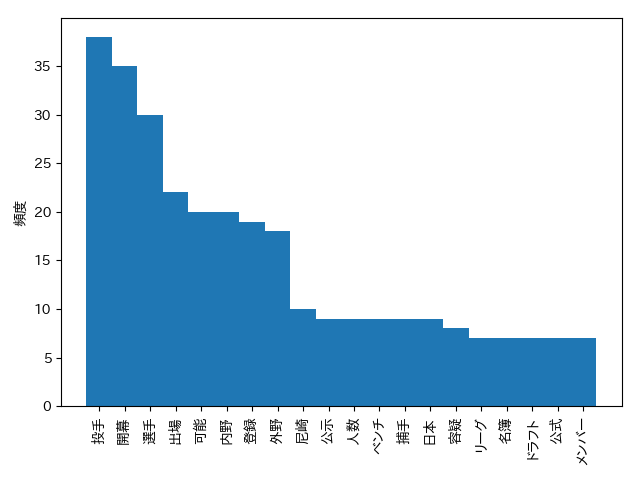
時節柄、春の選抜高校野球大会に関するニュースが多そうな事が見て取れる.
最後によく見る word cloud を作成.
font = "/System/Library/Fonts/ヒラギノ丸ゴ ProN W4.ttc"
wc = wordcloud.WordCloud(width=800, height=400, font_path=font, collocations=False)
wc = wc.generate_from_frequencies(nouns)
wc.to_file('wordcloud.png')

今回、MeCab 用いた日本語処理を見てみた. 日本語評価極性辞書 を使用すれば、sentiment analysis も可能.
補遺
- 2019-12-31
- updated get_news() to cope with the latest yahoo news format