YOLO
リアルタイムに物体検出が可能という YOLOv3 を Keras/Python を通して利用してみる. Keras を用いた YOLO の実装はこちら.
まずは、ImageNet の各種画像で物体検出を行ってみる. とある単語の WordNet ID を作成し、それを使用して対応する画像へのリンク一覧を ImageNet から得る.
from nltk.corpus import wordnet as wn
thing = 'cat'
synset = wn.synsets(thing)[0]
wnid = '{}{:08d}'.format(synset.pos(), synset.offset())
url = 'http://www.image-net.org/api/text/imagenet.synset.geturls?wnid={}'.format(wnid)
request = urllib.request.Request(url)
response = urllib.request.urlopen(request)
urls = response.read().decode('utf-8').split()
画像を入手し大きさを揃えて保存する.
import numpy as np
import cv2
IMG_SIZE = 400
def resize(img, size):
shape = img.shape[:2]
ratio = float(size)/max(shape)
scaled = tuple([int(x*ratio) for x in shape])
im = cv2.resize(img, (scaled[1], scaled[0]))
dw = size - scaled[1]
dh = size - scaled[0]
top, bottom = dh//2, dh-(dh//2)
left, right = dw//2, dw-(dw//2)
colour = [0, 0, 0]
return cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=colour)
response = urllib.request.urlopen(url)
data = np.frombuffer(response.read(), np.uint8)
img = cv2.imdecode(data, cv2.IMREAD_UNCHANGED)
resized_image = resize(img, IMG_SIZE)
cv2.imwrite('img.jpg', resized_image)
YOLO を使用して、保存した画像の物体検出を実行する.
from PIL import Image
import yolo
o = yolo.YOLO()
path = 'img.jpg'
image = Image.open(path)
r_image = o.detect_image(image)
r_image.show()
o.close_session()
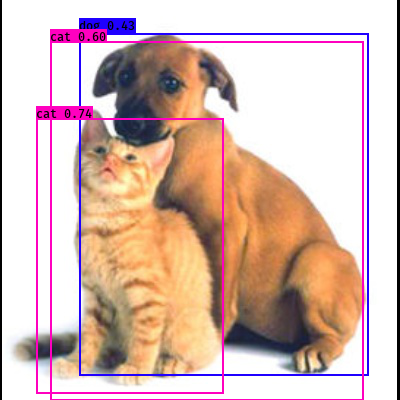
画像をスレッドを用いて素早くダウンロードし、YOLO で処理するコードはこちら. 幾つか結果を見てみると、まあ上手く認識できている.
| Too close ? | Good | Good |
|---|---|---|
 |
 |
 |
| Many cats | Cat & Dog | Good |
|---|---|---|
 |
 |
 |
その他のサンプルコード
--- a/yolo.py
+++ b/yolo.py
@@ -188,6 +188,7 @@ def detect_video(yolo, video_path, output_path=""):
prev_time = timer()
while True:
return_value, frame = vid.read()
+ if type(frame) == type(None): break
image = Image.fromarray(frame)
image = yolo.detect_image(image)
result = np.asarray(image)
Mask R-CNN
Mask R-CNN は物体認識とセグメンテーションを同時に行える. ImageNet から ‘pet’ をキーワードにして取得した画像に対して、Mask R-CNN を適用してみた. コードはこちら. 偶にクラッシュするが原因は未だ追及していない. GPU 無しの MacBook Air だと処理が重い. 結果はイマイチな気がするが、このような画像を対象には最適化されていないのだろう.
| 人物と冷蔵庫 | |
|---|---|
 |
 |
| 合体猫 | |
|---|---|
 |
 |
| 猫二匹 | |
|---|---|
 |
 |
| 分裂犬 | |
|---|---|
 |
 |
今回使用した技術は自動運転等に有用だと言われている.
補遺
- 2019-12-31
- TensorFlow >= v2 に対応した YOLOv3 の実装はこちら.