ひらがなのくずし字データ1を用いた画像認識を実装してみる. 使用したコードはこちら. 今回用いるのは 49文字のデータセット. 文字毎の訓練用画像数を確認すると最大6千、最小千以下とかなりのばらつきが見られる.
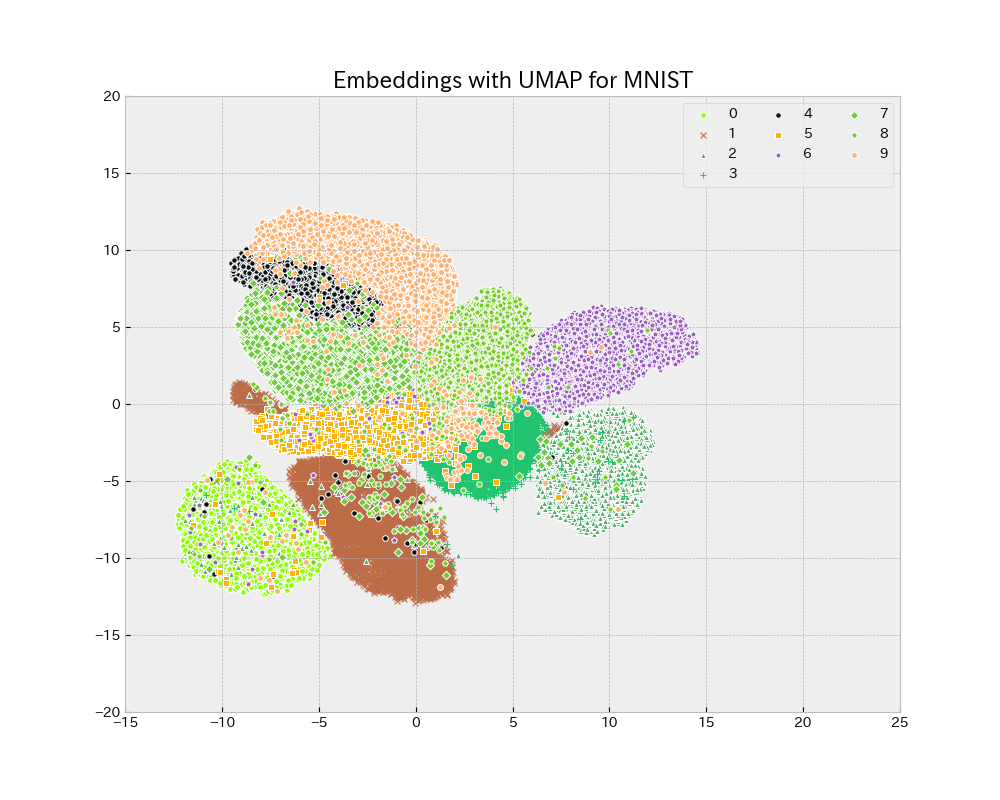
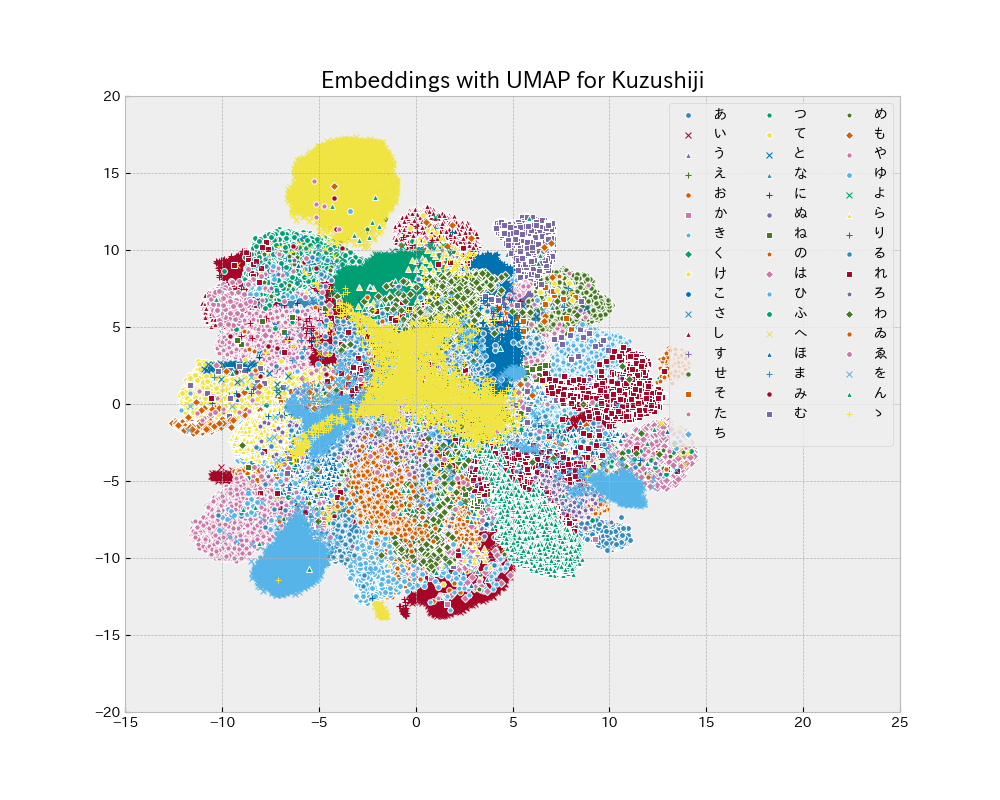
Uniform Manifold Approximation and Projection UMAP を用いて学習用データの2次元分布を見ると、MNIST と比較して ごちゃごちゃしており分類は難しそう.
| MNIST | Kuzushiji |
|---|---|
 |
 |
ConvNet には MNIST 画像データで 99.25% の精度を達成したモデル を流用する.
- 32個の3x3の畳み込みフィルタ層
- 64個の3x3の畳み込みフィルタ層
- 2x2の最大プーリング層
- 256個と49個のパーセプトロンからなる全結合層
Keras を用いたモデルの実装は以下の様になる. モデルの要約を確認すると学習すべき変数の数は約240万個.
model = Sequential()
model.add(Conv2D(32, kernel_size=(3,3),
activation='relu',
input_shape=(img_rows,img_cols,1)))
model.add(Conv2D(64, kernel_size=(3,3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(n_class, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
学習過程を見てみると、epoch=12 付近から顕著な学習の進展は見られない. 過学習は無い模様. GPU の無い MacBook Air で 1 epoch 当たり 12分程かかる.
テストデータで学習成果を確認する.
predict_classes = model.predict_classes(x_test)
print(classification_report(y_true, predict_classes)
適合率、再現率、F値は全て 0.87、0.87、0.87 であった.
混同行列を見てみると、対角成分に色むらが見られる. 上手く訓練できた文字とそうでない文字があるということ.
F1値が 0.8以下の文字を拾ってみると、’な’ (0.80)、’ま’ (0.75)、’る’ (0.78)、’ゐ’ (0.75)、’ゝ’ (0.57) となっている. これらの文字を表示してみると判別は文脈が無ければ難しそう.
補遺
- 2019-12-31
- TensorFlow >= v2 では tf.random.set_seed(seed)、keras.callbacks.callbacks.History[‘accuracy’]、keras.callbacks.callbacks.History[‘val_accuracy’] を使用する.
-
“KMNIST Dataset” (created by CODH), adapted from “Kuzushiji Dataset” (created by NIJL and others), doi:10.20676/00000341 ↩